구글, 네이버, 다음, 야후, 네이트, 엠파스, 파란...
쟁쟁한 검색사이트, 포탈사이트들이 지금은 많이 있지만 과거에 포탈사이트가 그리 뜨지 않았을 때는 검색엔진을 가지고 문서나 정보를 찾는 일이 많았다.
사실 지금은 내가 검색엔진을 사용하고 있는지 안하고 있는지 의식하지 못할 정도로 생활 깊숙히 검색이 일반화 되어 있다. 각종 광고에서도 검색창에 OOO라고 치라고 하고 말이다.
요즘은 검색엔진하면 구글을 많이 떠올린다. 물론, 네이버나 다음같은 포탈에서도 많은 검색을 제공하긴 하지만 순수한 검색사이트로 보긴 어렵다. 과거에는 검색엔진별로 몇만개, 몇백만개의 웹문서를 수집했으나 하는 것이 그 검색엔진의 성능을 나타내는 척도였으나 하드웨어 가격이 많이 내려가고 수집기술, 저장기술이 굉장히 발달된 요즘은 그러한 부분을 일일이 언급하는 일은 거의 없다.
그럼 검색엔진에서는 어떠한 방식으로 웹문서를 수집할까?
흔히 웹로봇이라 불리는 것들은 어떻게 인터넷상의 웹문서(HTML문서)를 수집할까?
몇가지 방법이 있겠지만 가장 단순한 방법을 소개할까 한다.
일반적으로 웹로봇이 인터넷을 돌아다니면서 웹문서를 수집한다고 표현하지만 보통 생각하는 것처럼 웹로봇이 사이트를 일일이 돌아다니면서 즉, 웹로봇이 불리우는 프로그램이 각각의 사이트에 들어가서 데이터를 가져오는 것은 아니다.
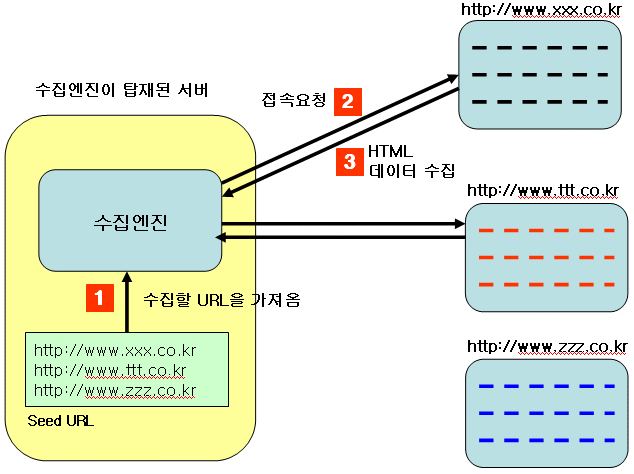
[그림 1 수집엔진 ]
그림에서 보는 것과 같이 수집엔진은 Seed(시드)라고 불리는 URL 목록을 가지고 있다. Seed는 수집엔진이 방문해야 할 웹사이트들의 주소를 저장해 놓은 것이다.
(1) 수집엔진이 먼저 Seed를 읽어 방문할 URL을 알아낸 다음
(2) 해당 URL에 접속 요청을 한다. 일반적으로 사용자가 브라우저 주소창에 URL을 입력하고 엔터를
치는 것과 같다고 생각하면 된다.
(3) 접속이 되고 나면 해당 웹사이트는 수집엔진이 요청한 URL의 HTML 데이터를 수집엔진쪽으로
보내준다. 사용자는 브라우저를 통해서 요청을 하므로 웹사이트가 보내주는 HTML 코드를
브라우저가 다시 변환하여 사람이 보기 편한 형태로 변환하여 주지만 수집엔진은
브라우저가 아니므로
<html> <head> .....</head> <body> ..... </body> </html>
이런 코드를 그대로 받아들인다.
수집엔진은 이 HTML 코드를 분석하여 웹페이지의 제목, 본문, 작성일자 등의 속성값을 뽑아낸다.
Seed에 등록되어 있는 URL을 대상으로 위와 같은 과정을 반복하여 수행한다. 그러면 수집엔진은 사용자가 Seed에 등록한 웹사이트의 데이터를 모두 수집할 수 있게 된다.
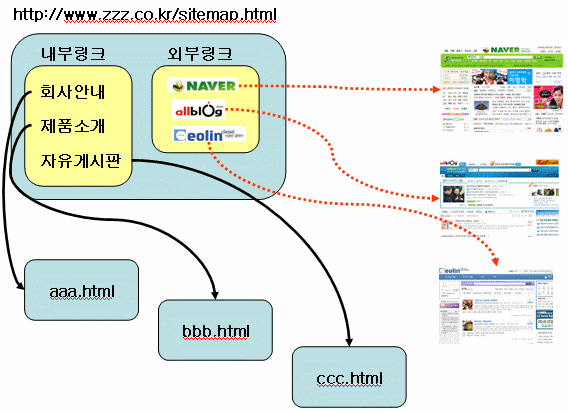
[ 그림 2 사이트 맵]
거의 모든 웹사이트는 Sitemap을 가지고 있다. 자기 사이트의 지도같은 것으로 그 사이트에 담고 있는 모든 페이지를 바로 접근할 수 있도록 모든 주소를 가지고 있고 또한 관련된 외부 사이트의 주소도 가지고 있다. 검색엔진에서 가장 중요하게 생각하는 것 중 하나가 바로 사이트맵이다. 일반적으로 검색엔진이 처음 방문하는 곳이기도 하다.
사이트맵을 분석하여 해당 사이트의 모든 주소를 알아내고 그 주소를 기초로 하여 데이터를 수집한다. 또한, 사이트맵에 걸려 있는 각종 외부 링크를 분석하여 새로 수집할 URL 정보를 알아낸다.
사이트맵의 HTML을 살펴보면 일반적으로 다음과 같다. 그림 2를 기초로 설명하면
<a href="aaa.html">회사안내</a><a href="bbb.html">제품소개</a><a href="ccc.html">자유게시판 </a><a href="http://naver.com">네이버이미지</a><a href="http://www.allblog.net">올블로그이미지/a><a href="http://www.eolin.com">이올린이미지</a>
>내부링크는 www.zzz.co.kr 사이트의 내부 웹페이지를 가리키는 것이고 외부링크는 여타 인터넷 상의 웹사이트를 말하는 것이다.
[그림1]에서 수집엔진이 일반적으로 사이트맵을 처음으로 방문하면 수집엔진은 사이트맵의 HTML 코드를 받아 다음에 방문(접속)할 내부 URL을 얻어낸다.
링크는 보통 <a href 로 시작하여 </a>로 끝나므로 HTML 코드에서 이러한 부분을 제거한 후 남은
aaa.html, bbb.html. ccc.html을 구한 후, 다음번에 방문할 URL로 저장한다.
그런 다음 aaa.html에 접속하여 같은 방식으로 HTML 코드를 얻어 제목, 본문, 작성일자 등 속성값을 구한다. 물론 aaa.html 에도 내부 또는 외부로의 링크가 걸려있으면 같은 방식으로 링크를 구한 후 저장한다.
naver.com 과 같은 외부 링크도 마찬가지다. 사이트맵에 걸려있는 모든 외부링크를 찾아서 다음에 방문할 URL로 저장한 후 앞의 모든 URL의 방문이 다 끝나면 꺼내서 방문한다. 이러한 과정이 반복된다.
이렇게 되면 초기에 몇개의 Seed를 등록하지 않더라도 상당히 많은 량의 웹사이트를 수집할 수 있다.
물론 처음에 naver와 같은 포탈을 seed로 줄 수도 있고 일반적인 회사 홈페이지를 seed로 줄 수 있다.
그것은 얼마나 많은 웹사이트를 수집할 것이냐 따라 차이가 있다.
물론, 일반적인 웹로봇의 경우는 제약사항이 몇가지 있다.
첫째, 사이트맵이 플래시로 되어 있는 경우는 HTML 코드를 뽑아내지 못하기 때문에 다음번에 방문할 URL을 구할 수가 없다.
둘째, 사이트맵이 자바스크립트 즉, <a href="javascript:goList(100)")> 와 같이 구성된 경우도 다음번에 방문할 URL을 구할 수 없으므로 수집엔진이 그 부분에서 종료된다.
셋째, 다음번에 방문할 URL을 얻었지만 그 웹사이트가 로그인을 해야 하는 경우는 수집엔진이 아이디와 비밀번호를 입력할 수 없므로 데이터를 수집하지 못한다.
이러한 제약사항을 풀기 위하여 전문적인 수집엔진들이 등장하고 있다.
간단하게나마 웹로봇의 동작원리에 대해서 나열하였다.
사실은 URL 중복처리, HTML 태그 제거 등 좀더 복잡한 단계가 있으나 우선 개념적으로만 알아보았다.
웹로봇에 대해서 궁금한 분들께 조금이라도 도움이 되었길 바란다.